Self-Supervised Material and Texture Representation Learning for Remote Sensing Tasks
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2022 (Oral Presentation)
Peri Akiva, Matthew Purri, and Matthew Leotta
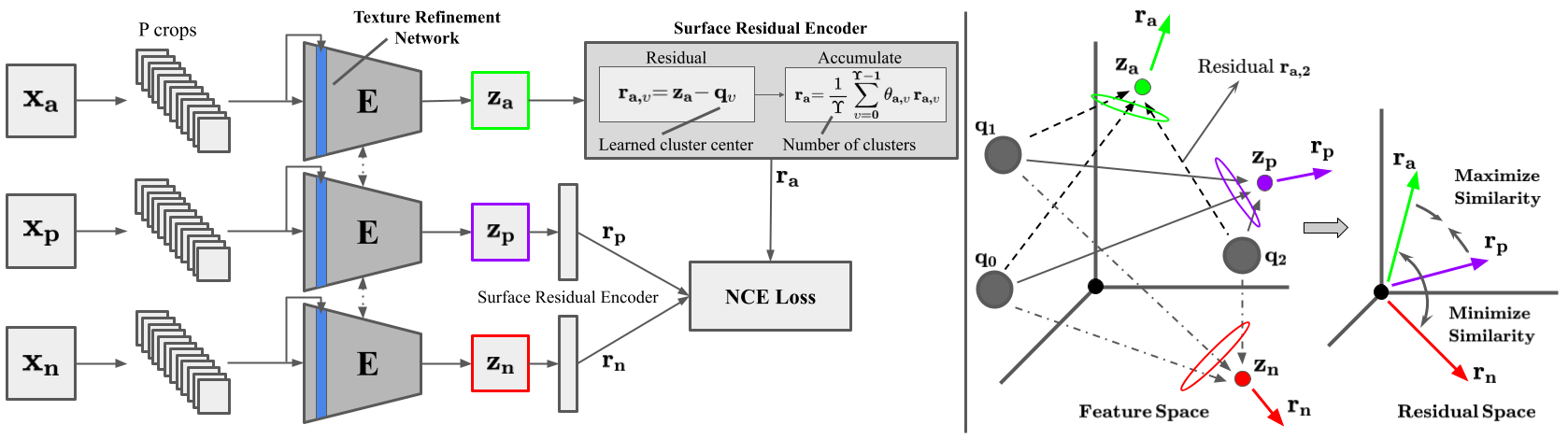
(Left) MATTER: anchor, positive, and negative images $x_a$, $x_p$, and $x_n$ are densely windowed to $P$ crops which are fed to encoder $E$, and correspond to output features $z_a$, $z_p$, and $z_n$. Crops are also fed to the Texture Refinement Network (shown in blue) which amplifies activation of low-level features to increase their impact in deeper layers. The encoder's output is then fed to the Surface Residual Encoder to generate patch-wise cumulative residuals, which represents affinity between input data and all learned clusters. A residual vector between feature output $z_a$ and cluster $\upsilon$ is denoted as $r_{a,\upsilon}$. Output learned residuals, cluster weights, and number of clusters are noted as $r$, $\theta$, and $\Upsilon$ respectively. (Right) Simplified example of the contrastive objective with $\Upsilon=3$. Residuals from learned clusters are extracted and averaged for all crops as representations of correlation between inputs and all clusters. Best viewed in zoom and color.
Abstract
Self-supervised learning aims to learn image feature representations without the usage of manually annotated labels. It is often used as a precursor step to obtain useful initial network weights which contribute to faster convergence and superior performance of downstream tasks. While self-supervision allows one to reduce the domain gap between supervised and unsupervised learning without the usage of labels, the self-supervised objective still requires a strong inductive bias to downstream tasks for effective transfer learning. In this work, we present our material and texture based self-supervision method named MATTER (MATerial and TExture Representation Learning), which is inspired by classical material and texture methods. Material and texture can effectively describe any surface, including its tactile properties, color, and specularity. By extension, effective representation of material and texture can describe other semantic classes strongly associated with said material and texture. MATTER leverages multi-temporal, spatially aligned remote sensing imagery over unchanged regions to learn invariance to illumination and viewing angle as a mechanism to achieve consistency of material and texture representation. We show that our self-supervision pre-training method allows for up to 24.22% and 6.33% performance increase in unsupervised and fine-tuned setups, and up to 76% faster convergence on change detection, land cover classification, and semantic segmentation tasks.
Code and dataset.Video
Paper

Paper and Supplement (Arxiv)
@misc{akiva2021self,
title={Self-Supervised Material and Texture Representation Learning for Remote Sensing Tasks},
author={Akiva, Peri and Purri, Matthew and Leotta, Matthew},
eprint={2112.01715},
archivePrefix={arXiv},
primaryClass={cs.CV}
year = {2021}