Self-Supervised Material and Texture Representation Learning for Remote Sensing Tasks Summer 2021
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2022 (Oral Presentation)
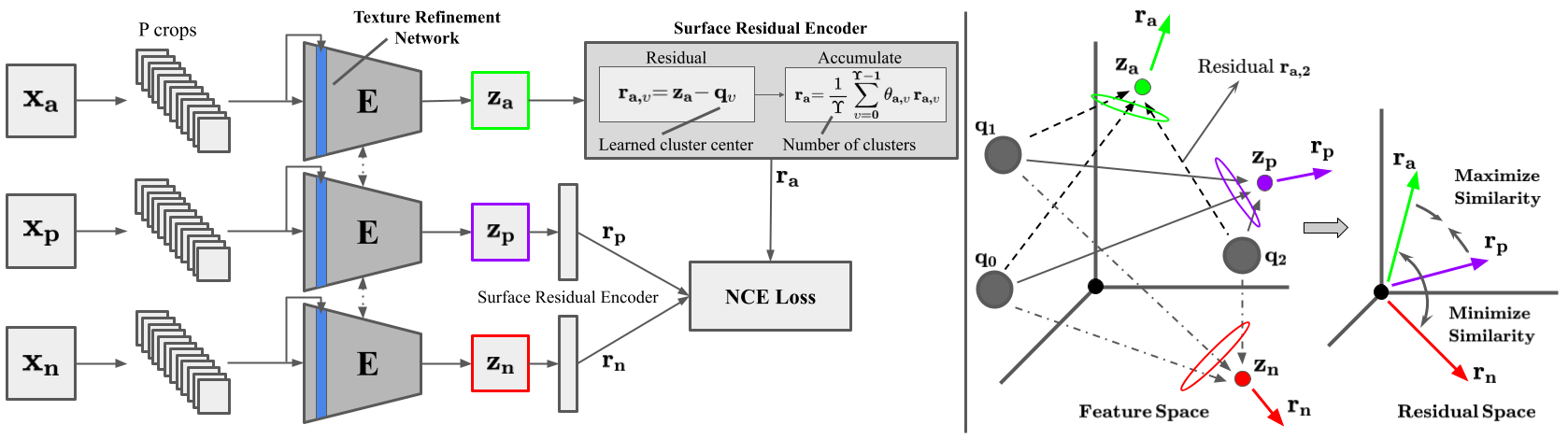
Self-supervised learning aims to learn image feature representations without the usage of manually annotated labels. It is often used as a precursor step to obtain useful initial network weights which contribute to faster convergence and superior performance of downstream tasks. While self-supervision allows one to reduce the domain gap between supervised and unsupervised learning without the usage of labels, the self-supervised objective still requires a strong inductive bias to downstream tasks for effective transfer learning. In this work, we present our material and texture based self-supervision method named MATTER (MATerial and TExture Representation Learning), which is inspired by classical material and texture methods. Material and texture can effectively describe any surface, including its tactile properties, color, and specularity. By extension, effective representation of material and texture can describe other semantic classes strongly associated with said material and texture. MATTER leverages multi-temporal, spatially aligned remote sensing imagery over unchanged regions to learn invariance to illumination and viewing angle as a mechanism to achieve consistency of material and texture representation. We show that our self-supervision pre-training method allows for up to 24.22\% and 6.33\% performance increase in unsupervised and fine-tuned setups, and up to 76\% faster convergence on change detection, land cover classification, and semantic segmentation tasks. Code and dataset.
AI on the Bog: Monitoring and Evaluating Cranberry Crop Risk Summer 2020
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2021
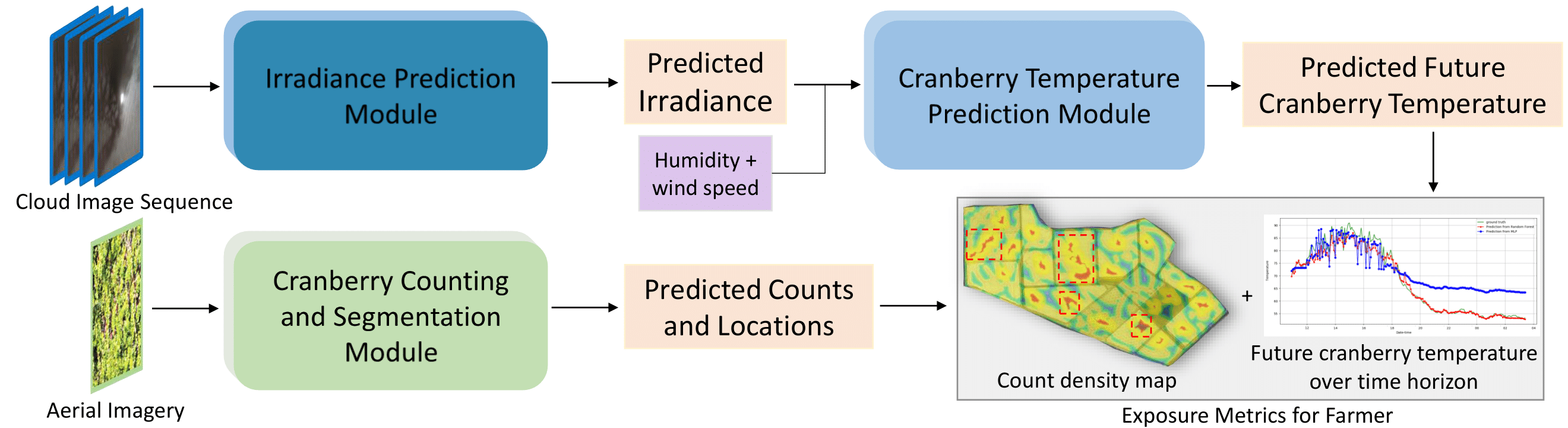
Machine vision for precision agriculture has attracted considerable research interest in recent years. The goal of this paper is to develop an end-end cranberry health monitoring system to enable and support real time cranberry over-heating assessment to facilitate informed decisions that may sustain the economic viability of the farm. Toward this goal, we propose two main deep learning-based modules for: 1) cranberry fruit segmentation to delineate the exact fruit regions in the cranberry field image that are exposed to sun, 2) prediction of cloud coverage conditions to estimate the inner temperature of exposed cranberries. We develop drone-based field data and ground-based sky data collection systems to collect video imagery at multiple time points for use in crop health analysis. Extensive evaluation on the data set shows that it is possible to predict exposed fruit’s inner temperature with high accuracy (0.02% MAPE) when irradiance is predicted with 8.41-20.36% MAPE in the 5-20 minutes time horizon. With 62.54% mIoU for segmentation and 13.46 MAE for counting accuracies in exposed fruit identification, this system is capable of giving informed feedback to growers to take precautionary action (\eg, irrigation) in identified crop field regions with higher risk of sunburn in the near future. Though this novel system is applied for cranberry health monitoring, it represents a pioneering step forward in efficiency for farming and is useful in precision agriculture beyond the problem of cranberry overheating.
H2O-Net: Self-Supervised Flood Segmentation via Adversarial Domain Adaptation and Label Refinement Summer 2020
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2021
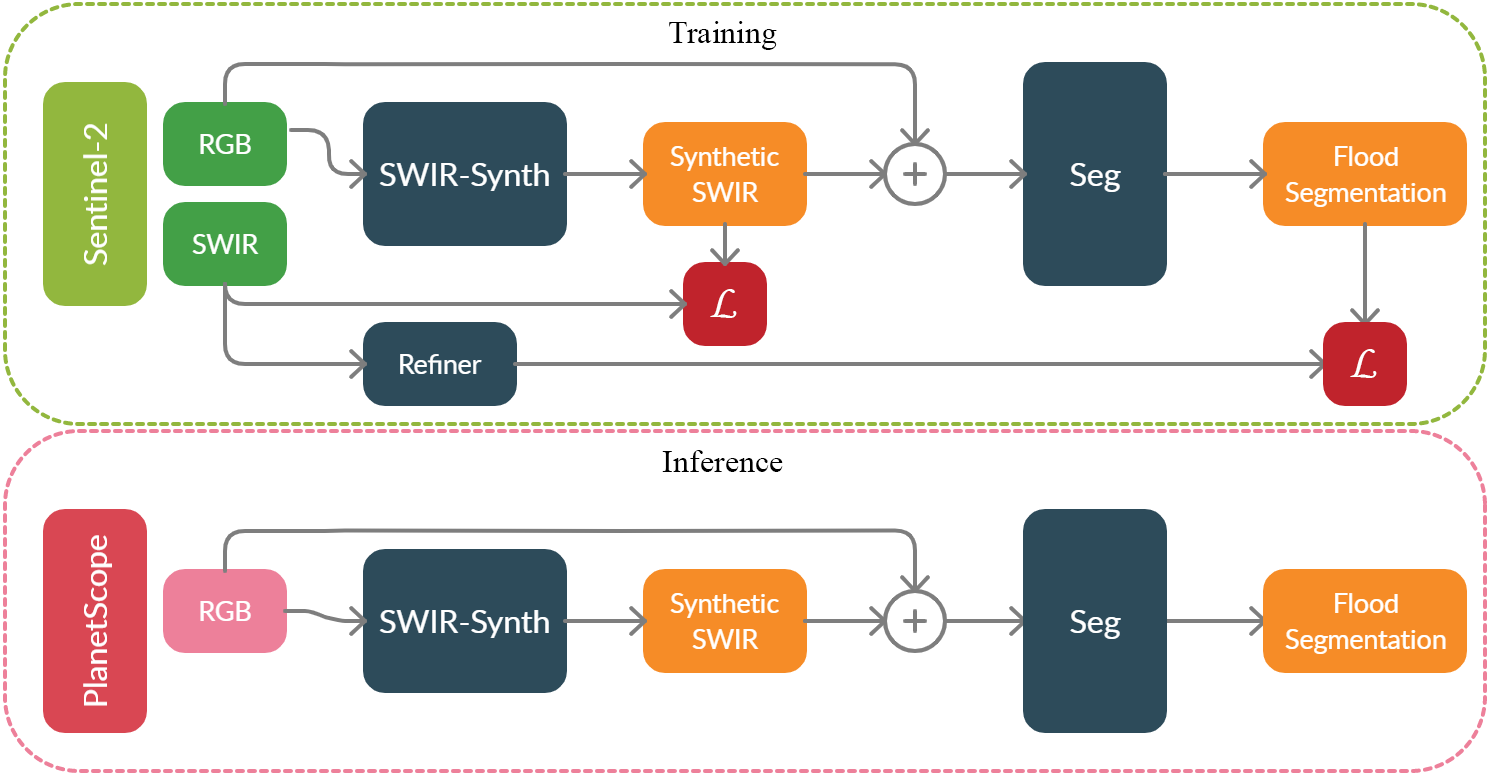
Accurate flood detection in near real time via high resolution, high latency satellite imagery is essential to prevent loss of lives by providing quick and actionable information. Instruments and sensors useful for flood detection are rarely available in low resolution, low latency satellites with region re-visit periods of up to 16 days, making flood alerting systems that use such satellite unreliable. Accurate flood detection in near real time via high resolution, high latency satellite imagery is essential to prevent loss of lives by providing quick and actionable information. Instruments and sensors useful for flood detection are rarely available in low resolution, low latency satellites with region re-visit periods of up to 16 days, making flood alerting systems that use such satellite unreliable. This work presents H2O-Network, a self supervised deep learning method to segment floods from satellites and aerial imagery by bridging domain gap between low and high latency satellite and coarse-to-fine label refinement. H2O-Net learns to synthesize signals highly correlative with water presence as a domain adaptation step for semantic segmentation in high resolution satellite imagery. Our work also proposes a self-supervision mechanism, which does not require any hand annotation, used during training to generate high quality ground truth data. We demonstrate that H2O-Net outperforms the state-of-the-art semantic segmentation methods on satellite imagery by 16.43% for the task of flood segmentation. We also show that our method may be beneficial to other domains that make use of reflectance properties.
Finding Berries: Segmentation and Counting of Cranberries using Point Supervision and Shape Priors Spring 2020
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2020 (Oral Presentation)
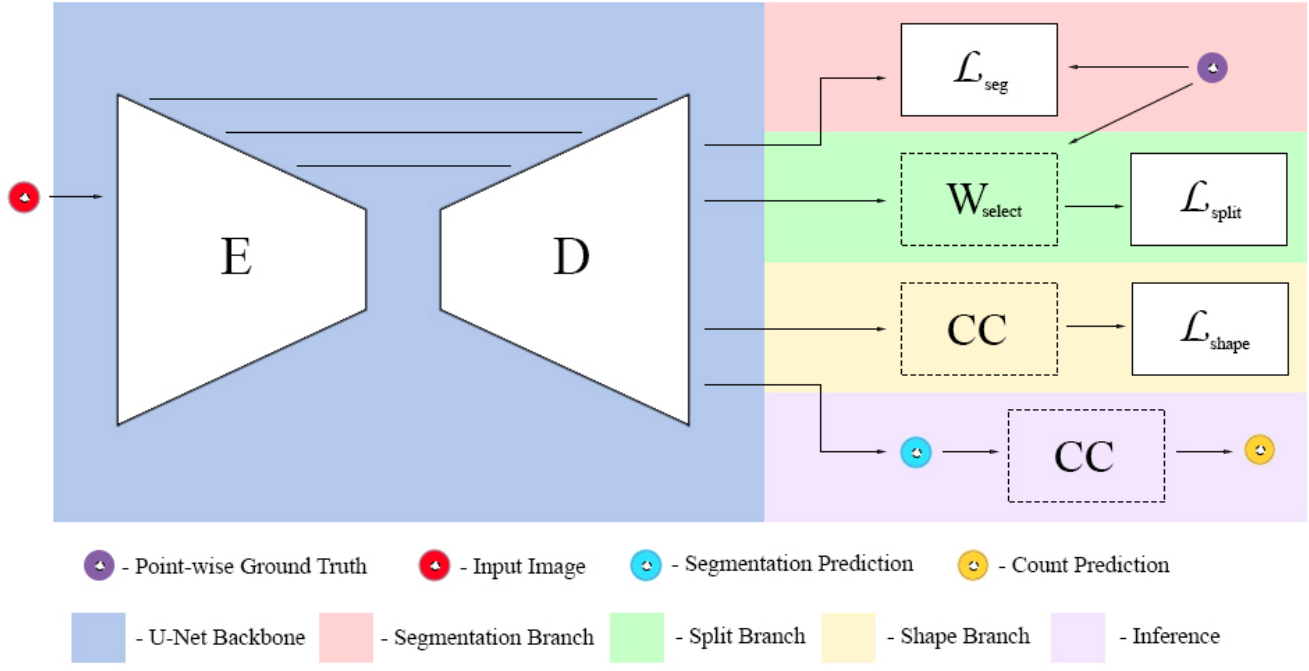
Precision agriculture has become a key factor for increasing crop yields by providing essential information to decision makers. In this work, we present a deep learning method for simultaneous segmentation and counting of cranberries to aid in yield estimation and sun exposure predictions. Notably, supervision is done using low cost center point annotations. The approach, named Triple-S Network, incorporates a three-part loss with shape priors to promote better fitting to objects of known shape typical in agricultural scenes. Our results improve overall segmentation performance by more than 6.74% and counting results by 22.91% when compared to state-of-the-art. To train and evaluate the network, we have collected the CRanberry Aerial Imagery Dataset (CRAID), the largest dataset of aerial drone imagery from cranberry fields. This dataset will be made publicly available.
ViewSynth: Learning Local Features from Depth using View Synthesis Fall 2019
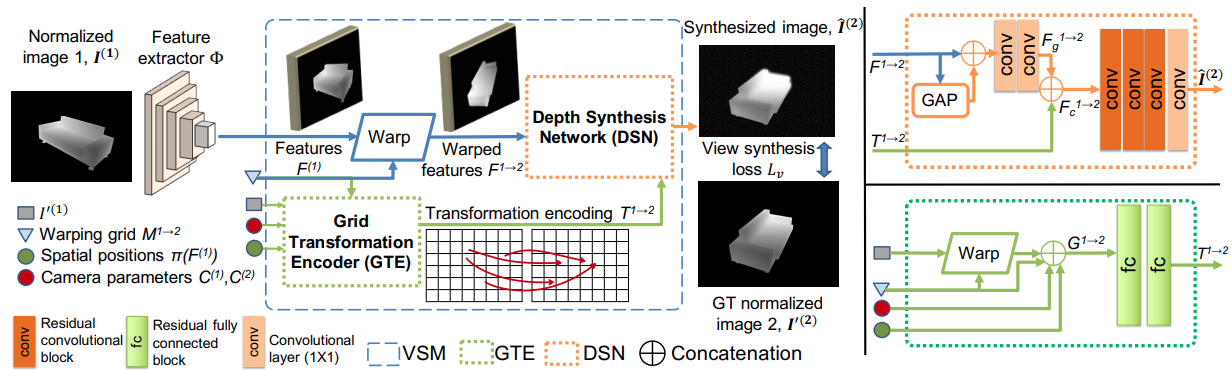
BMVC, 2020
The rapid development of inexpensive commodity depth sensors has made keypoint detection and matching in the depth image modality an important problem in computer vision. Despite great improvements in recent RGB local feature learning methods, adapting them directly in the depth modality leads to unsatisfactory performance. Most of these methods do not explicitly reason beyond the visible pixels in the images. To address the limitations of these methods, we propose a framework ViewSynth, to jointly learn: (1) viewpoint invariant keypoint-descriptor from depth images using a proposed Contrastive Matching Loss, and (2) view synthesis of depth images from different viewpoints using the proposed View Synthesis Module and View Synthesis Loss. By learning view synthesis, we explicitly encourage the feature extractor to encode information about not only the visible, but also the occluded parts of the scene. We demonstrate that in the depth modality, ViewSynth outperforms the state-of-the-art depth and RGB local feature extraction techniques in the 3D keypoint matching and camera localization tasks on the RGB-D datasets 7-Scenes, TUM RGBD and CoRBS in most scenarios. We also show the generalizability of ViewSynth in 3D keypoint matching across different datasets.The rapid development of inexpensive commodity depth sensors has made keypoint detection and matching in the depth image modality an important problem in computer vision. Despite great improvements in recent RGB local feature learning methods, adapting them directly in the depth modality leads to unsatisfactory performance. Most of these methods do not explicitly reason beyond the visible pixels in the images. To address the limitations of these methods, we propose a framework ViewSynth, to jointly learn: (1) viewpoint invariant keypoint-descriptor from depth images using a proposed Contrastive Matching Loss, and (2) view synthesis of depth images from different viewpoints using the proposed View Synthesis Module and View Synthesis Loss. By learning view synthesis, we explicitly encourage the feature extractor to encode information about not only the visible, but also the occluded parts of the scene. We demonstrate that in the depth modality, ViewSynth outperforms the state-of-the-art depth and RGB local feature extraction techniques in the 3D keypoint matching and camera localization tasks on the RGB-D datasets 7-Scenes, TUM RGBD and CoRBS in most scenarios. We also show the generalizability of ViewSynth in 3D keypoint matching across different datasets.