ViewSynth: Learning Local Features from Depth Using View Synthesis
BMVC, 2020
Jisan Mahmud, Peri Akiva, Rajat Vikran Singh, Spondon Kundo, Kuan-Chuan Peng, Jan-Michael Frahm
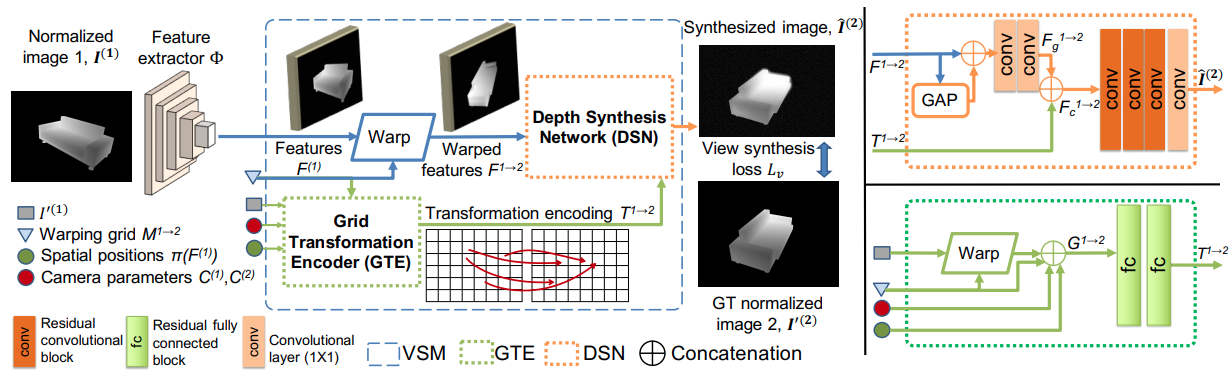
The ViewSynth framework. Dense features, keypoints and descriptors are extracted from depth images I^{1}, I^{2}. Contrastive Matching Loss supervises keypoint and descriptor learning. Simultaneously, View Synthesis Module trained with View Synthesis Loss synthesizes depth image from I^{2}’s view from I^{1}’s features.
Abstract
The rapid development of inexpensive commodity depth sensors has made keypoint detection and matching in the depth image modality an important problem in computer vision. Despite great improvements in recent RGB local feature learning methods, adapting them directly in the depth modality leads to unsatisfactory performance. Most of these methods do not explicitly reason beyond the visible pixels in the images. To address the limitations of these methods, we propose a framework ViewSynth, to jointly learn: (1) viewpoint invariant keypoint-descriptor from depth images using a proposed Contrastive Matching Loss, and (2) view synthesis of depth images from different viewpoints using the proposed View Synthesis Module and View Synthesis Loss. By learning view synthesis, we explicitly encourage the feature extractor to encode information about not only the visible, but also the occluded parts of the scene. We demonstrate that in the depth modality, ViewSynth outperforms the state-of-the-art depth and RGB local feature extraction techniques in the 3D keypoint matching and camera localization tasks on the RGB-D datasets 7-Scenes, TUM RGBD and CoRBS in most scenarios. We also show the generalizability of ViewSynth in 3D keypoint matching across different datasets.The rapid development of inexpensive commodity depth sensors has made keypoint detection and matching in the depth image modality an important problem in computer vision. Despite great improvements in recent RGB local feature learning methods, adapting them directly in the depth modality leads to unsatisfactory performance. Most of these methods do not explicitly reason beyond the visible pixels in the images. To address the limitations of these methods, we propose a framework ViewSynth, to jointly learn: (1) viewpoint invariant keypoint-descriptor from depth images using a proposed Contrastive Matching Loss, and (2) view synthesis of depth images from different viewpoints using the proposed View Synthesis Module and View Synthesis Loss. By learning view synthesis, we explicitly encourage the feature extractor to encode information about not only the visible, but also the occluded parts of the scene. We demonstrate that in the depth modality, ViewSynth outperforms the state-of-the-art depth and RGB local feature extraction techniques in the 3D keypoint matching and camera localization tasks on the RGB-D datasets 7-Scenes, TUM RGBD and CoRBS in most scenarios. We also show the generalizability of ViewSynth in 3D keypoint matching across different datasets.
Video
Paper

Paper and Supplement (Arxiv)
@article{mahmud2019viewsynth,
title={ViewSynth: Learning Local Features from Depth using View Synthesis},
author={Mahmud, Jisan and Akiva, Peri and Singh, Rajat Vikram and Kundu, Spondon and Peng, Kuan-Chuan and Frahm, Jan-Michael},
journal={arXiv preprint arXiv:1911.10248},
year={2019}